Web Crawler is a program that browses the network in an automated and organized manner. Web crawlers are also called as ants, automatic indexers, bots, worms and Spiders too. The process it engages in is referred as Web crawling. Is intended to crawl over the internet and collect the desired information. Generally crawlers are used by Search engines to collect the information, It collects the links visited and many more important information that the search engines use in there algorithms.
Crawler based search engines performs three steps
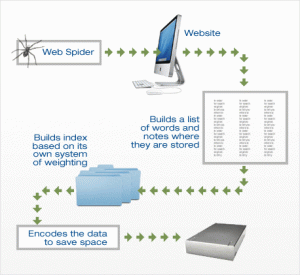
1. Crawling : It recursively follows the hyperlinks present to find the another document.
2. Indexing : It helps to fond the information in faster way. The index is actually a catlog. Evrey change in the web page is recorded here
It consists of two steps
Parsing: It removes the link for further crawling, removes JavaScript, tag, comments etc.
Hashing: After parsing is done it is encoded into the number
3. Searching: From the millions of the documents only the top relevant pages are tobe displayed. It involves certain steps to follow:
- Parse the query.
- Convert words to WordIDs using hash functions
- Compute rank for every document
- Sorting of the documents
- List top documents
Though this process seems to be very simple it is not so. Web itself makes crawling difficult.
Large volume of the Web
Extremely fast change in the Web
Dynamic page generation
This characteristic of the Web makes a wide variety of the crawlable URLs
Web crawlers works according to it predefined polices.
Selection policy: looking at the large volume of the web, it is nearly impossible to download the entire web and crawl it, so it downloads the portion of the web and work on it. It has a policy to prioritize the web pages. The importance of the web pages is decided and then it is prioritized.
Re-visit policy: We know that the nature of the web is very dynamic, by the time the crawling of the site is finished many events occur which include new creation, updation or deletion. There are many policies under re-visiting that are implemented that include Uniform policy, Proportional policy and optimal policy.
Politeness policy: It includes how less to overload websites. Web crawler uses many resources.
Parallelization policy: This states that a crawler runs multiple process in parallel. It maximizes the download and minimizes the overhead. In short it coordinates distributed Web crawlers.